
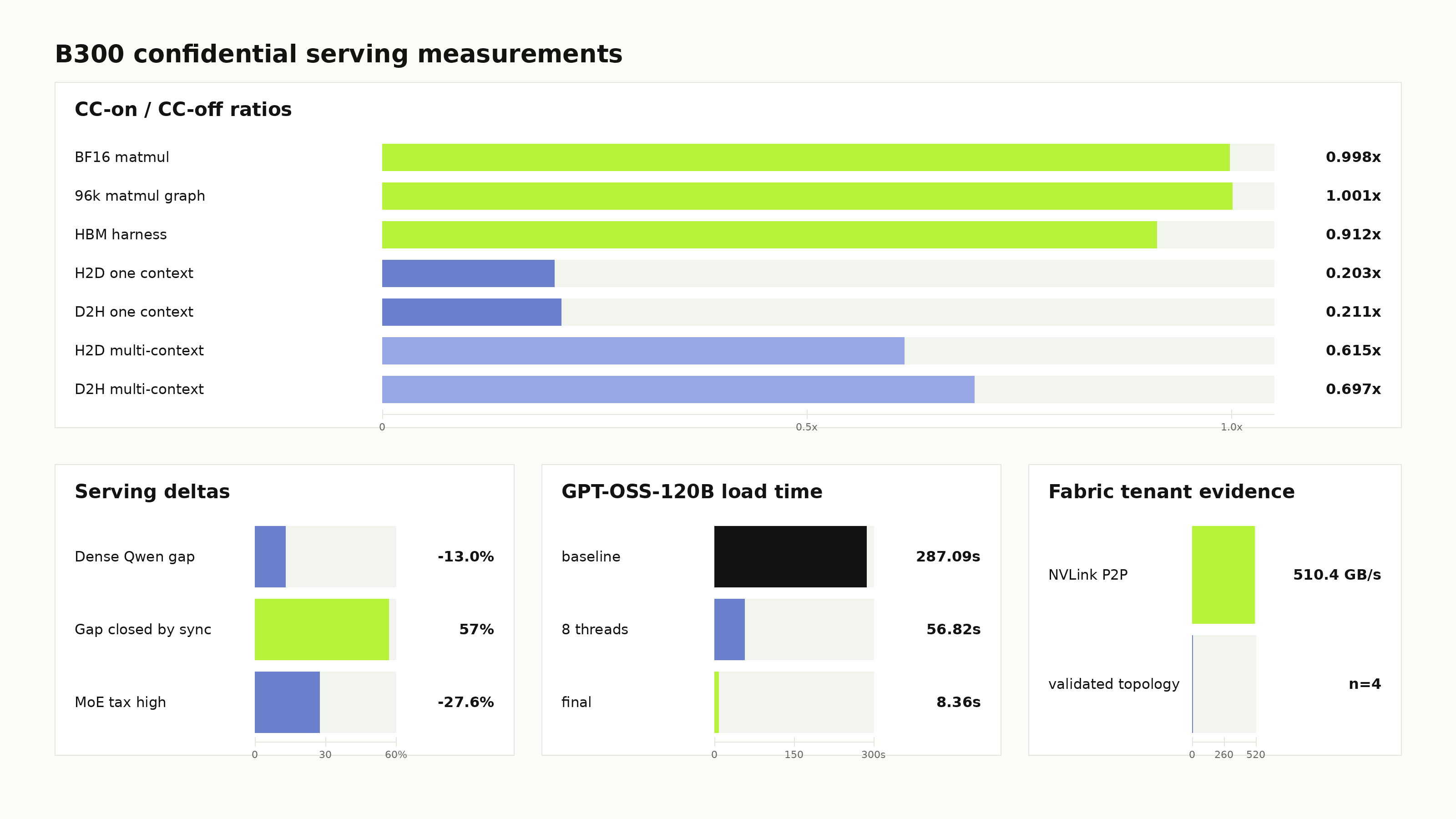
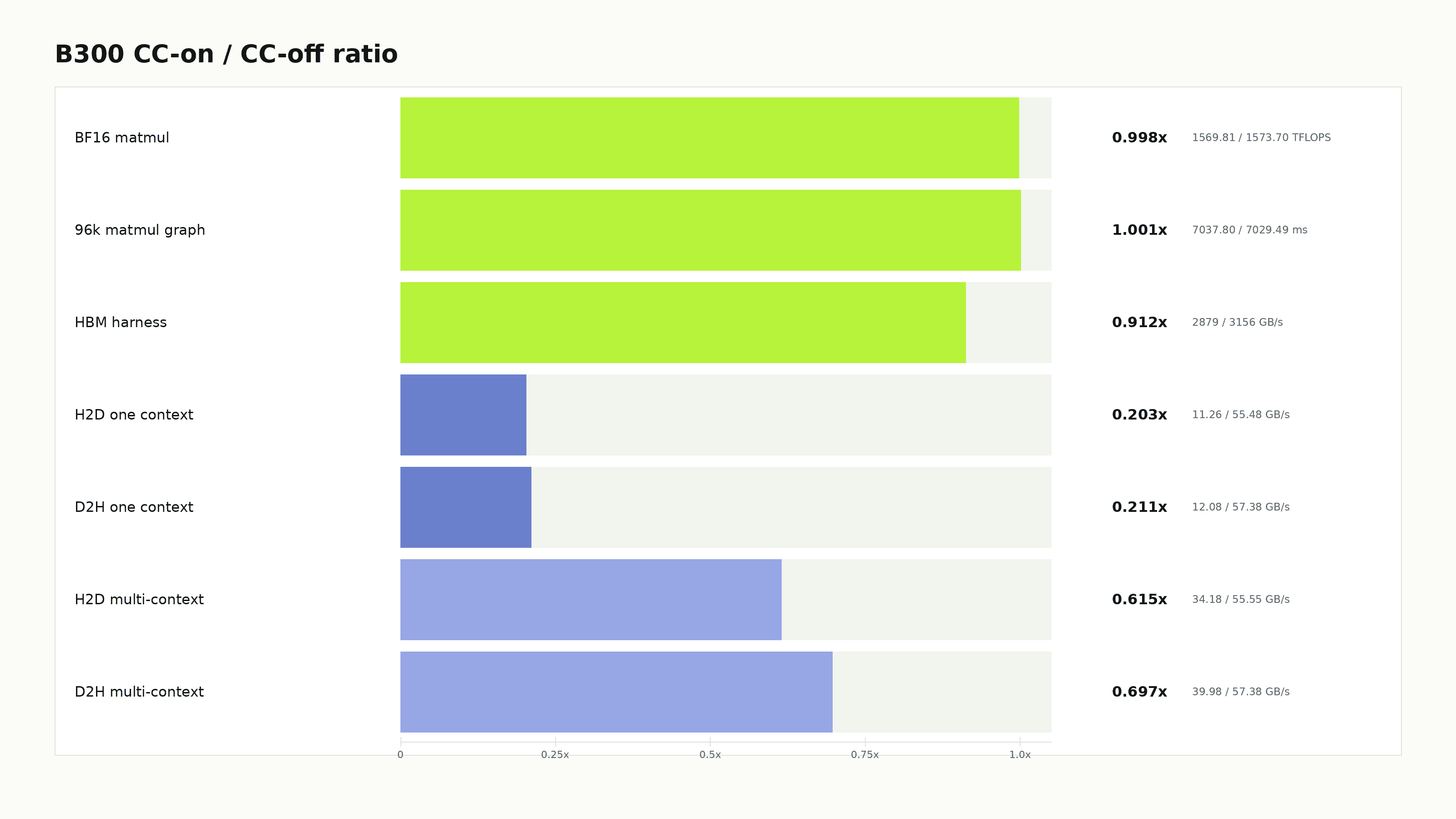
Blackwell changes the confidential AI performance story. On NVIDIA B300, BF16 matmul under GPU Confidential Computing runs at 0.998x of non-confidential performance. A CUDA graph chaining 96,000 matmuls runs at 1.0012x. The tensor cores and HBM are already close to native.
The serving stack still loses throughput because another path has become the scarce resource: the confidential VM to GPU bridge. In the paper The Serialized Bridge, we measured B300 and RTX Pro 6000 Blackwell systems and found a consistent law: host/device movement becomes serialized, high-setup-cost, and effectively synchronous inside a CUDA context.
The new performance model
The bridge has three properties that matter for LLM serving:
- Same-context host/device transfers serialize. More CUDA streams do not create more bridge bandwidth.
non_blocking=Truecopies still block the CPU thread under GPU-CC.- Small crossings pay a fixed setup toll, measured at roughly 330 microseconds per call.
This split shows up immediately in the microbenchmarks. B300 BF16 matmul is 0.998x CC-on versus CC-off. A long CUDA graph is 1.0012x. A 1 GiB HBM-style harness is 0.912x. Single-context H2D transfer falls to 0.203x, and D2H to 0.211x.
The operational rule is simple: treat every bridge crossing like a scheduled resource. Batch it, drain it, and avoid putting it on the critical path.
Why default runtime policy can reverse
Modern serving runtimes were built around cheap, asynchronous DMA. That assumption breaks under GPU-CC. vLLM's default async scheduling normally overlaps output drain with the next step. Under CC, those overlapping copies serialize on the same bridge channel, so the overlap overhead remains while the overlap benefit disappears.
In a B300 Qwen3.6-27B-FP8 dense-decode run at concurrency 128, the default CC-on async path delivered 3550 tok/s. Disabling async scheduling raised it to 4104 tok/s, closing 57% of the CC gap. Under the sync policy, the residual CC tax was about 1%.
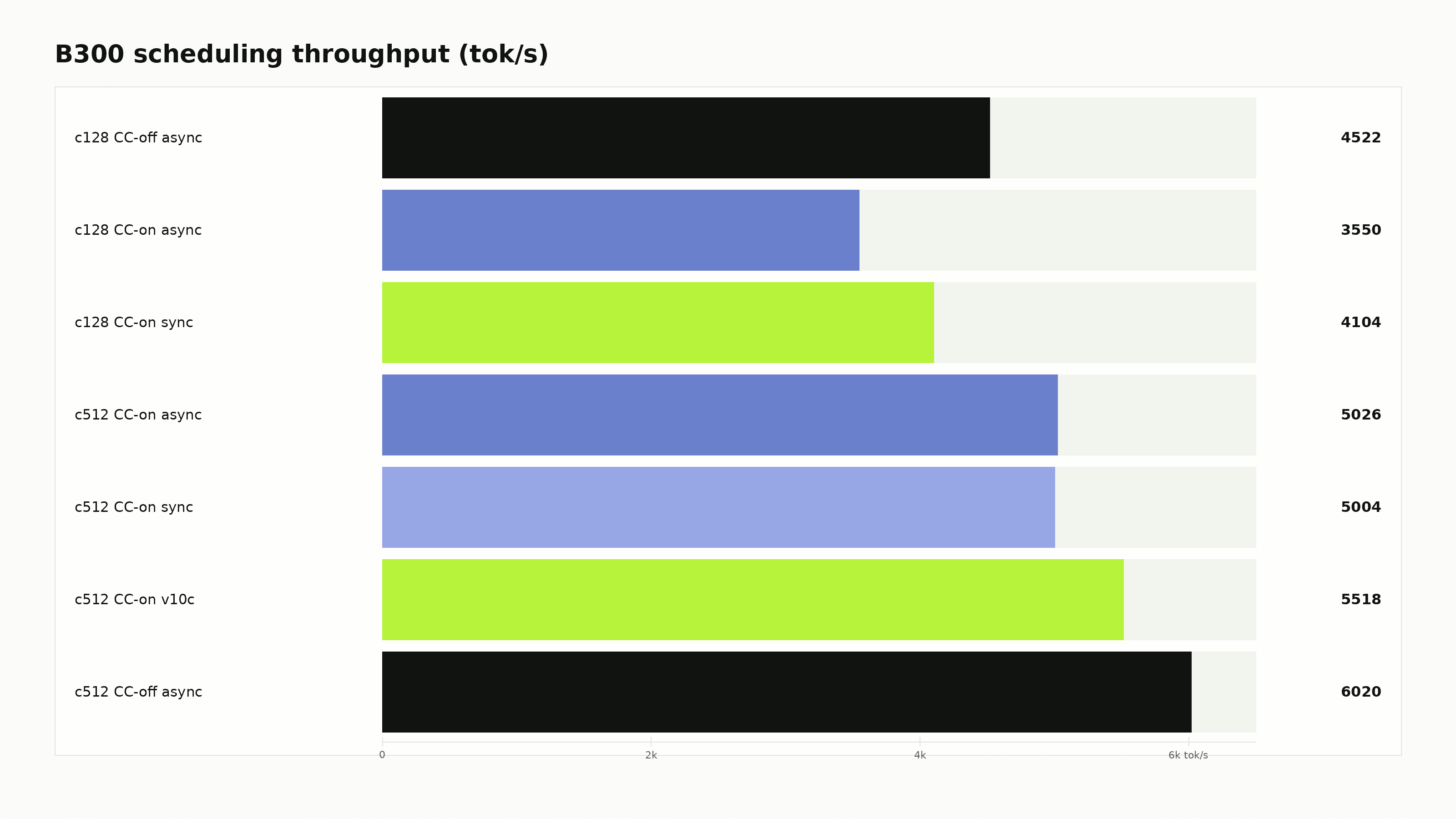
A worker-thread drain patch goes further by moving the blocking drain off the engine thread. In a qualified high-concurrency B300 run, it reached 5518 tok/s at concurrency 512, within 8.3% of the non-confidential async gold path.
The broader lesson is the useful part: a confidential-serving runtime needs CC-mode-aware defaults. Drain before refill. Move blocking waits away from the hot thread. Use GPU residency more aggressively. Treat movement as a budget.
The workload tax follows movement
The CC tax is workload-shaped. Rate-capped online serving can hide it. Resident dense decode pays a moderate cost. MoE routing and KV restore pay more because they create more bridge traffic.
In the B300 serving rows from the paper:
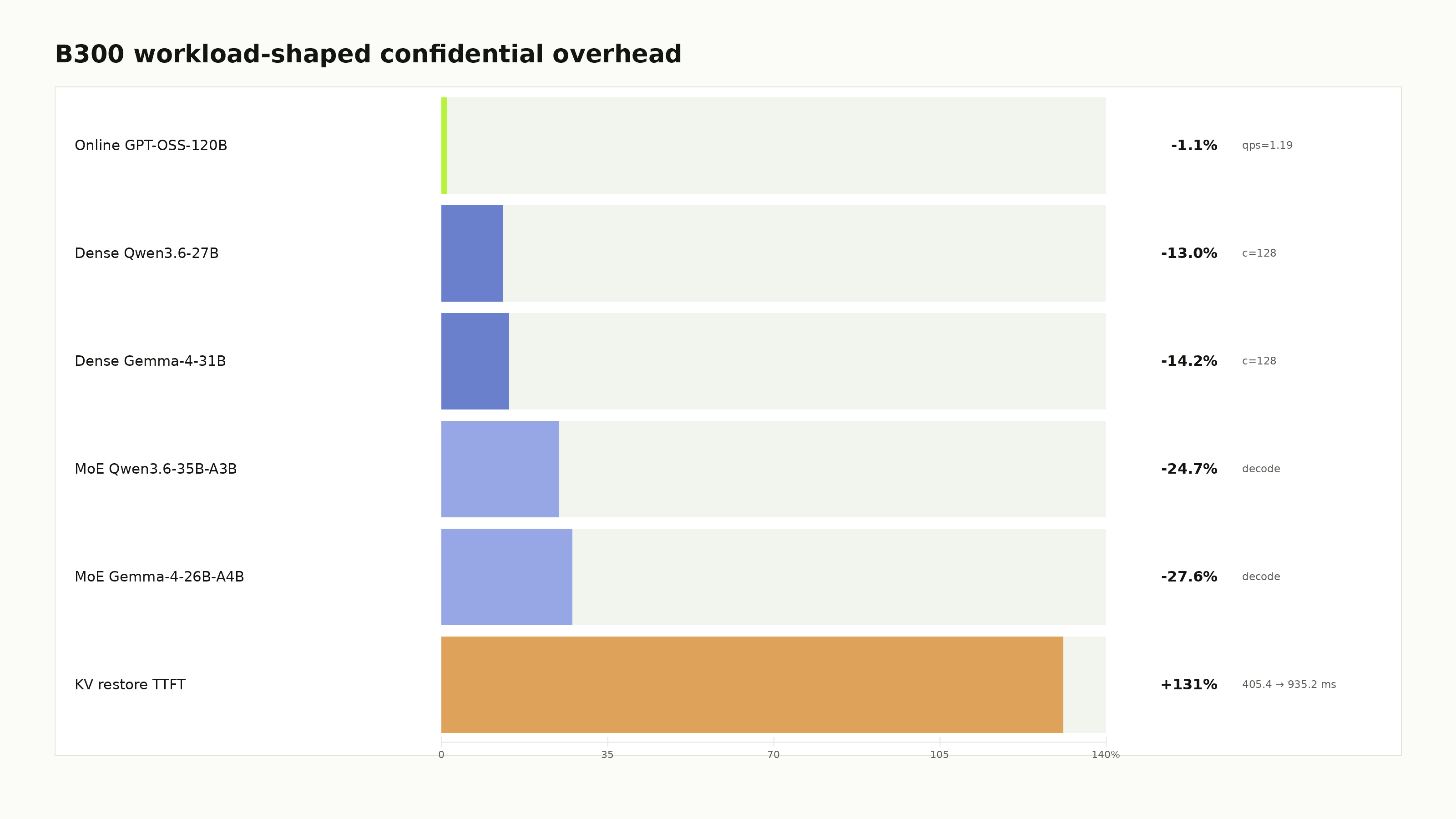
- MLPerf-shaped online serving for GPT-OSS-120B at qps=1.19 lost 1.1%.
- Dense Qwen3.6-27B-FP8 lost 13.0%.
- Dense Gemma-4-31B-it at c=128 lost 14.2%.
- MoE decode lost 24.7-27.6%.
- KV restore warm TTFT rose from 405.4 ms to 935.2 ms, a +131% penalty.
This is the right way to evaluate confidential inference capacity. Ask what crosses the bridge, how often, and whether the runtime schedules those crossings deliberately.
Cold start is a bridge problem too
The same model explains model loading. Loading GPT-OSS-120B into a confidential GPU through the default safetensors path took 287.09 seconds on B300. That number barely changed on RTX Pro 6000, which points at the software path: serialized parsing, staging, and single-context secure transfer.
A CC-aware loader fixes the movement pattern. It fans weight shards across pooled CUDA contexts, reuses secure lifecycles, prewarms the pool, and tears down asynchronously. On B300, load time fell from 287.09 seconds to 8.36 seconds.
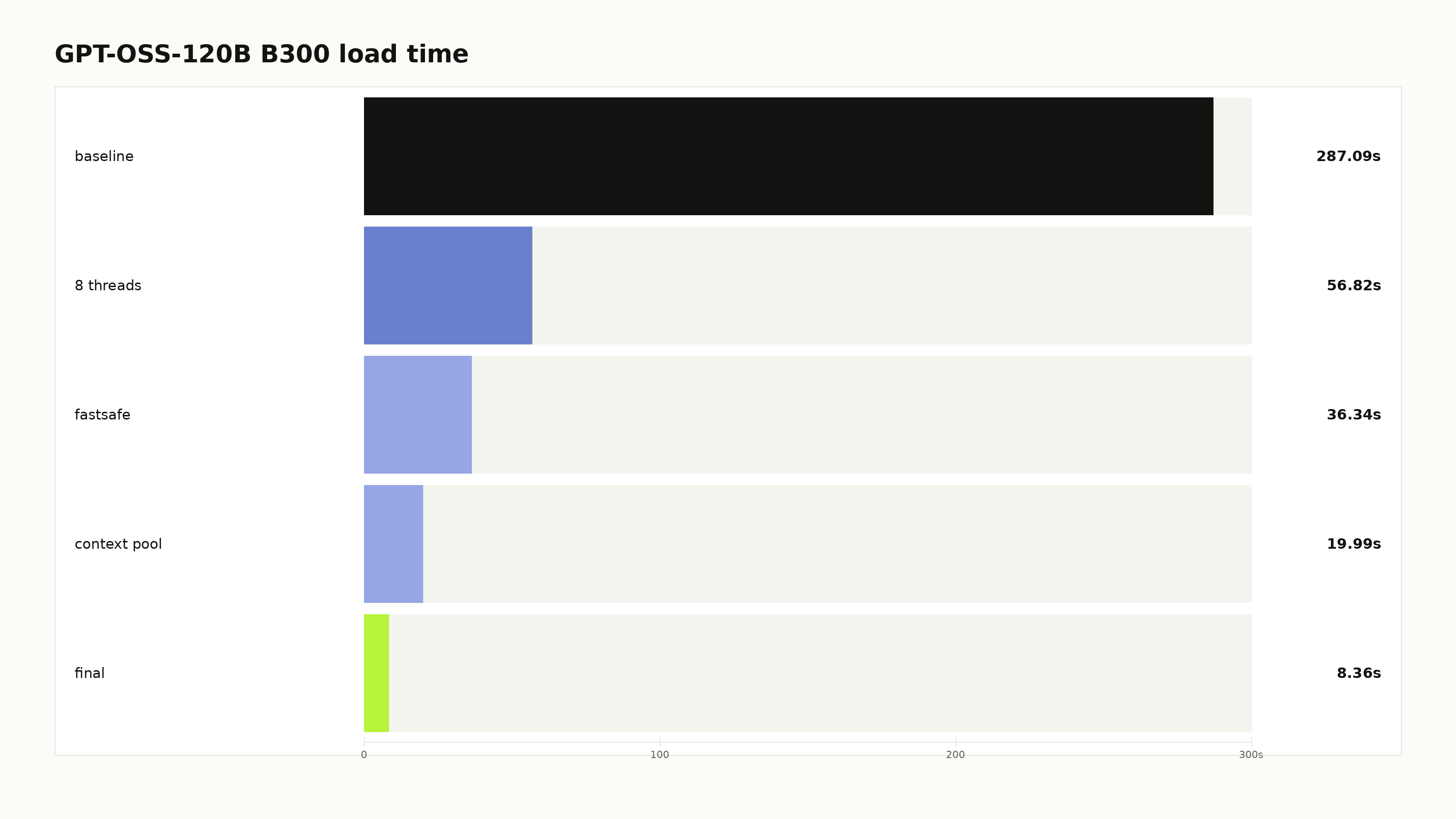
Cold start is a product feature. At 287 seconds, capacity is hard to treat as elastic. At 8.4 seconds, confidential serving becomes much easier to schedule, recover, and scale.
KV state follows the same rule. Under churn, restoring a 1.1 GiB prefix raised B300 warm TTFT by +131%. Synchronous scheduling brought it back near parity. On Pro 6000, reuse-aware offload cut spill volume from 2.3 GiB to 2.3 MB and improved CC-on warm TTFT 2.97x.
Blackwell also changes the tenant boundary
B300 HGX adds a second change: the confidential tenant can be a partition of an NVSwitch fabric. The paper qualifies confidential multi-GPU tenants on B300, including 510.4 GB/s CUDA peer-to-peer bandwidth inside a two-GPU confidential CVM.
We also validated four-GPU confidential tenant topology and concurrent isolated tenant partitions. The remaining trust boundary is the fabric control plane: Fabric Manager identity and exact NVSwitch routing state need stronger tenant-verifiable evidence.
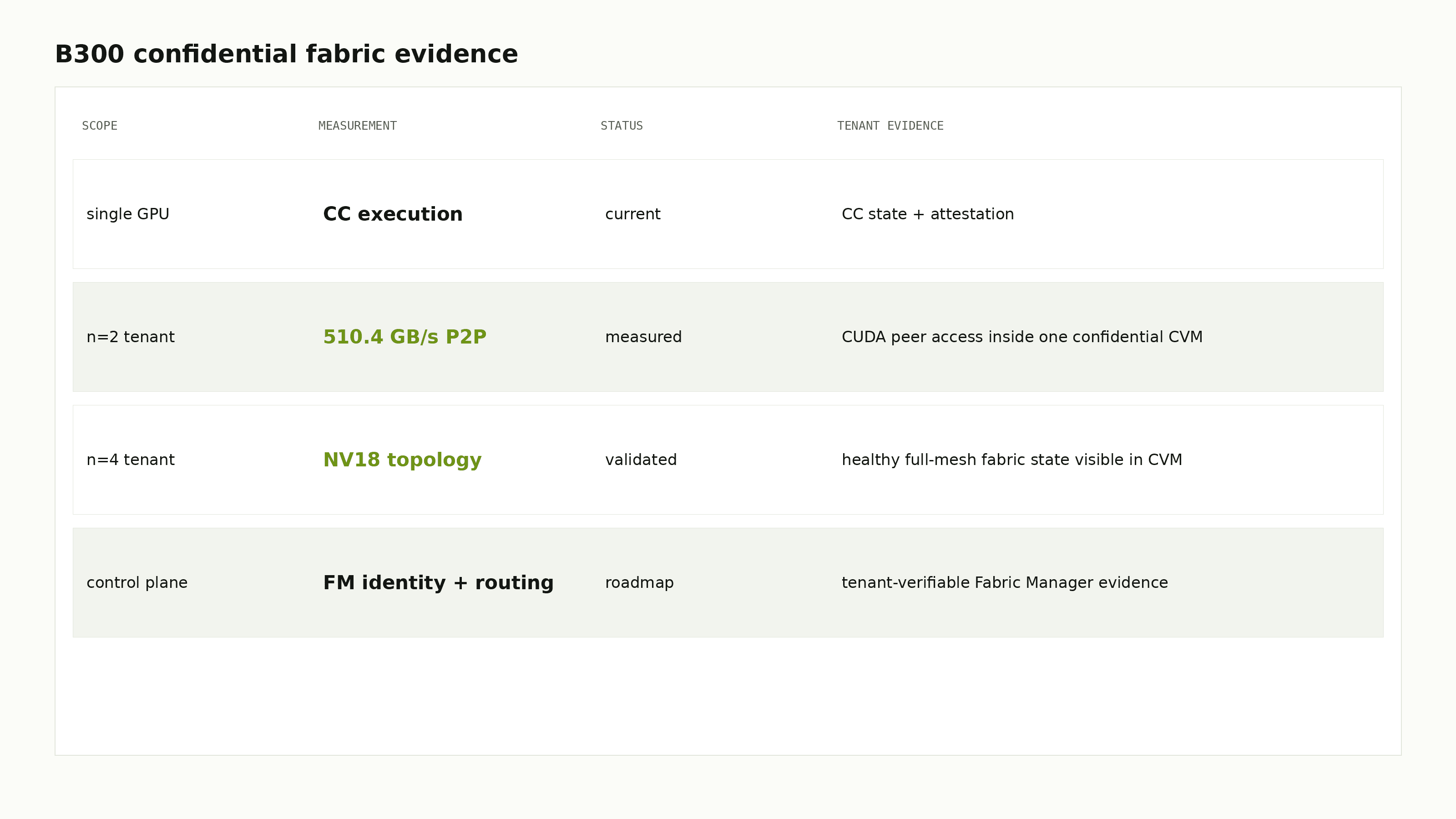
For a confidential AI platform, fabric becomes both a scheduling object and a trust object. The control plane needs to expose GPU-CC state, fabric health, partition identity, and eventually attestable fabric routing.
What this means for confidential AI
Phala's confidential AI platform already sits at the layer where these decisions matter: runtime defaults, model loading, KV policy, tenant scheduling, attestation, and dstack-driven CVM orchestration.
The paper gives us five practical rules for production confidential serving:
- Treat bridge crossings as scheduled resources.
- Get host/device transfer concurrency from pooled contexts.
- Make runtime defaults CC-mode-aware.
- Buy residency for weights and KV state.
- Schedule and attest the fabric as part of the tenant boundary.
Blackwell makes confidential inference faster, but it also makes the old runtime assumptions more expensive. The next generation of confidential AI platforms will be judged by how well they respect the serialized bridge and how clearly they prove the fabric they allocate.
Read the paper: The Serialized Bridge: Understanding and Recovering LLM Serving Performance under Blackwell GPU Confidential Computing.